作者:阿中哥 + AI 協助彙整。 【本文約有2,610字】
一:前言,Qwen2.5-72B 語言模型基準測試比較分析
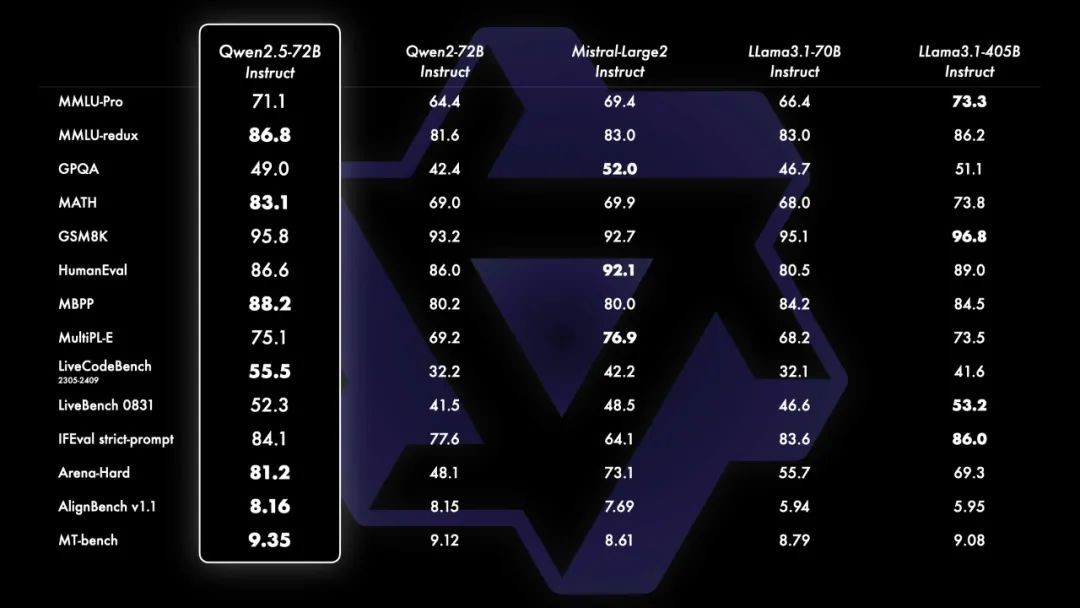
這份報告將詳細分析五個語言模型(Qwen2.5-72B Instruct、Qwen2-72B Instruct、Mistral-Large2 Instruct、Llama3.1-70B Instruct 和 Llama3.1-405B Instruct)在多項基準測試中的表現。這些基準測試涵蓋了多種自然語言處理(NLP)任務,包括數學解題、程式碼生成、機器翻譯等多種應用場景。
二:比較項目的簡單解釋
每個比較項目的簡單解釋,用比較白話的方式說明,讓國中生也可以了解:
- MMLU-Pro (多項選擇理解專業測試):這是一種像學校考試那樣的測試,機器要選出正確的答案,測試範圍涵蓋專業知識,例如科學、歷史等專業領域的題目。
- MMLU-redux (多項選擇理解測試重新版本):跟上面類似,但題目範圍更廣,包含更多學科的考題,讓機器回答各種不同類型的問題。
- GPQA (全局段落問題回答測試):這個測試是給機器一段文字,然後問它一個問題,機器必須根據那段文字來找出答案。
- MATH (數學測試):這就是讓機器解答數學題,測試它解決數學問題的能力。
- GSM8K (數字序列推理測試):這是一種測試,機器要根據給出的數字推測出規律或答案,類似數學裡的邏輯推理題。
- HumanEval (編程代碼人類評估測試):這個測試是給機器一些程式設計的問題,讓機器寫程式碼,然後人類會檢查它的程式是否正確。
- MBPP (編程問題解決能力測試):這也是程式設計測試,測試機器解決程式問題的能力,看它能不能寫出正確的程式來解決問題。
- MultiPL-E (多程式語言代碼測試):這裡測試機器能不能在多種不同的程式語言中寫出正確的程式,像是 Python、Java 等等。
- LiveCodeBench 2305-2409 (即時編碼基準測試 2305-2409):這測試機器能不能即時寫出正確的程式碼來解決問題,就像程式比賽一樣。
- LiveBench 0831 (即時基準測試 0831):這也是類似程式設計的測試,但測試範圍可能更廣,機器必須在即時狀況下寫出正確的程式。
- IFEval strict-prompt (嚴格提示一下的程式測試):這個測試會給機器一些很具體的指示,然後要求機器寫出符合這些指示的程式碼。
- Arena-Hard (競技場難度測試):這是一個很難的測試,機器要面對非常複雜的問題,像是一場比賽,看看誰的表現最好。
- AlignBench v1.1 (對齊基準測試 v1.1):這個測試主要是看機器在處理多個任務時,能不能正確對齊它的結果,也就是說,機器需要處理多個步驟並且能得到正確的答案。
- MT-bench (機器翻譯測試):這是一個測試機器翻譯能力的測試,機器要把一段話從一種語言翻譯成另一種語言,測試它翻譯得好不好。
三:項目比較解析
- MMLU-Pro (多項選擇理解專業測試)
這項測試類似於學校中的多項選擇考試,重點測試模型在專業知識(例如科學、歷史、數學等)領域的理解力。
- 最高分:Llama3.1-405B Instruct(73.3)
- 解讀:Llama3.1-405B 表現最佳,這意味著它在專業知識方面的理解能力最強。
- MMLU-redux (多項選擇理解測試重新版本)
這是 MMLU 的重新版本,範圍更廣,測試模型在回答多樣化的學科問題時的表現。
- 最高分:Qwen2.5-72B Instruct(86.8)
- 解讀:Qwen2.5-72B 顯示出它在多學科的理解力中表現最為優異。
- GPQA (全局段落問題回答測試)
這項測試提供一段文章,模型需要從文章中找出答案。它衡量模型的閱讀理解和資訊檢索能力。
- 最高分:Mistral-Large2 Instruct(52.0)
- 解讀:Mistral-Large2 表現最好,顯示它在處理長文本和回答具體問題方面有優勢。
- MATH (數學測試)
這項測試讓模型解決數學問題,評估其數學推理能力。
- 最高分:Qwen2.5-72B Instruct(83.1)
- 解讀:Qwen2.5-72B 的數學解題能力領先,適合用於需要精確計算和推理的應用場景。
- GSM8K (數字序列推理測試)
這個測試主要是數字序列推理,模型需要推斷出數字之間的規律。
- 最高分:Llama3.1-405B Instruct(96.8)
- 解讀:Llama3.1-405B 在數字推理能力上表現出色,特別是在分析數據和序列的邏輯推理中表現最佳。
- HumanEval (編程代碼人類評估測試)
這項測試要求模型生成程式碼,然後由人類檢查程式碼的正確性和品質。
- 最高分:Mistral-Large2 Instruct(92.1)
- 解讀:Mistral-Large2 在生成準確和有效程式碼的能力上表現最好,對於程式碼自動生成的應用非常有潛力。
- MBPP (編程問題解決能力測試)
這是一個針對解決程式設計問題的測試,模型需要撰寫解決特定問題的程式碼。
- 最高分:Qwen2.5-72B Instruct(88.2)
- 解讀:Qwen2.5-72B 在程式設計問題上的解決能力優於其他模型,適合用於程式自動化和解決方案生成。
- MultiPL-E (多程式語言代碼測試)
這項測試評估模型在不同程式語言中的表現,例如 Python、Java 等。
- 最高分:Mistral-Large2 Instruct(76.9)
- 解讀:Mistral-Large2 展現了它在多種程式語言中撰寫正確代碼的能力,這對於多語言編程環境中的應用非常有幫助。
- LiveCodeBench 2305-2409 (即時編碼基準測試 2305-2409)
這是一個即時編程測試,要求模型在有限的時間內完成程式設計任務。
- 最高分:Qwen2.5-72B Instruct(55.5)
- 解讀:Qwen2.5-72B 的即時編碼能力最佳,適合需要快速生成程式碼的場景。
- LiveBench 0831 (即時基準測試 0831)
這個測試也是即時程式設計,但涵蓋的範圍可能更廣,考察模型能否在即時情境下解決不同問題。
- 最高分:Llama3.1-405B Instruct(53.2)
- 解讀:Llama3.1-405B 在即時多樣問題的解決能力上更具優勢。
- IFEval strict-prompt (嚴格提示一下的程式測試)
這項測試會給模型非常具體的要求,檢查它能否按照這些要求生成符合規範的程式碼。
- 最高分:Llama3.1-405B Instruct(86.0)
- 解讀:Llama3.1-405B 表現卓越,能在非常具體的指示下生成符合要求的程式碼。
- Arena-Hard (競技場難度測試)
這是非常困難的測試,專門設計來考驗模型的極限,讓模型處理高難度問題。
- 最高分:Qwen2.5-72B Instruct(81.2)
- 解讀:Qwen2.5-72B 表現最佳,適合需要處理複雜和困難問題的應用場景。
- AlignBench v1.1 (對齊基準測試 v1.1)
這個測試看模型在多任務處理中的表現,要求它同時解決多個步驟並得到正確的結果。
- 最高分:Qwen2.5-72B Instruct(81.6)
- 解讀:Qwen2.5-72B 在多任務處理中的表現最佳,適合需要同時處理多個步驟的工作流程。
- MT-bench (機器翻譯測試)
這是測試模型翻譯能力的基準,要求模型將一段文本從一種語言正確翻譯成另一種語言。
- 最高分:Qwen2.5-72B Instruct(9.35)
- 解讀:Qwen2.5-72B 的翻譯能力在測試中表現最佳,適合應用於多語言環境下的機器翻譯工作。
四:結論
根據這些測試結果,Qwen2.5-72B Instruct 在多數基準測試中表現最為優異,尤其是在數學、即時程式設計、機器翻譯和多任務處理等方面。這表明它具有很強的問題解決和推理能力。
Llama3.1-405B Instruct 則在專業知識測試、數字推理、即時基準測試等方面表現突出,顯示它在應用於這些特定任務中也有很好的潛力。
Mistral-Large2 Instruct 則在編程相關的測試(如 HumanEval 和 MultiPL-E)中表現優異,適合用於需要編寫準確程式碼的應用。
根據不同模型在這些測試中的表現,企業或研究機構可以根據需求選擇最適合的模型來應用於特定場景。
五:建議
- Qwen2.5-72B Instruct 適合需要強大推理和即時處理能力的應用,例如多語言翻譯系統、數學推理以及多任務處理。
- Llama3.1-405B Instruct 可以用於專業知識檢索、數據分析以及即時多任務解決方案。
- Mistral-Large2 Instruct 非常適合用於程式碼生成和軟體開發,特別是需要多語言支持的程式環境。
這些測試提供了對不同語言模型在多種應用場景下的深入理解,幫助選擇最適合的解決方案來應對實際需求。
六:後記
Mistral-Large2 真的非常優秀,在我工作實際使用 python 加速生成程式碼,它真的是最佳自動產碼工具。
如果它有類似 ChatGPT Plus 的 My GPT 功能,那就更完美了。