Qwen2.5-72B 語言模型基準測試比較分析
Qwen2.5-72B 語言模型基準測試比較分析
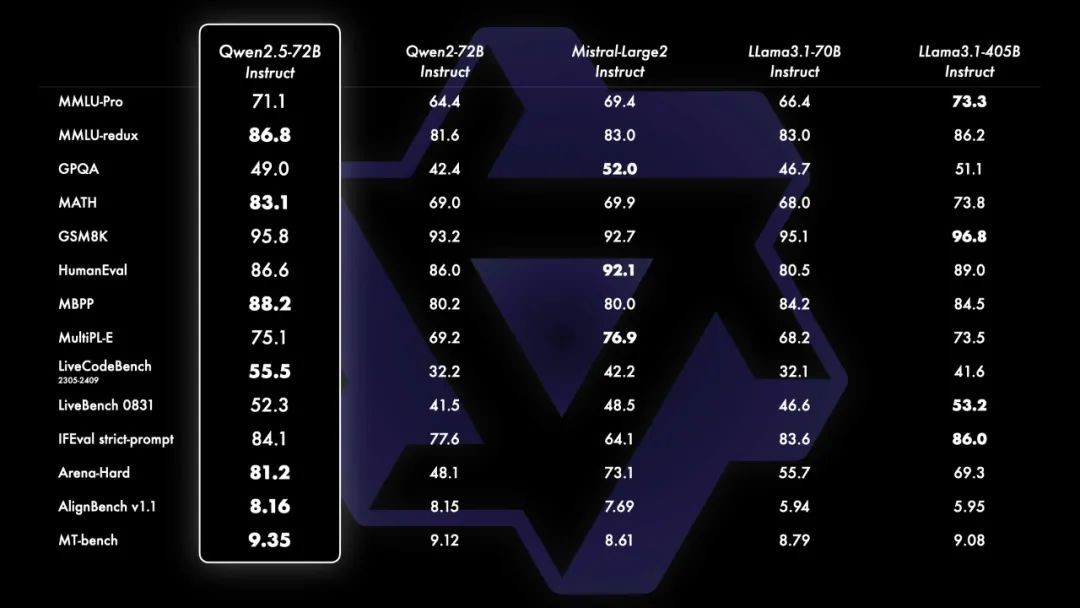
該網頁分析了多種語言模型在基準測試中的表現,特別是針對 Qwen2.5-72B 模型的性能進行深入探討。這些測試涵蓋了數學解題、程式碼生成、機器翻譯等多種自然語言處理任務。比較的模型包括 Qwen2.5-72B Instruct、Llama3.1-70B Instruct、Mistral-Large2 Instruct 等。結果顯示,Qwen2.5-72B 在多數測試中表現優異,特別是在數學推理、程式設計以及多任務處理等方面具有明顯的領先優勢。
Continue Reading
Qwen2.5-72B 語言模型基準測試比較分析